GNN系列1-GCN(Graph Convolutional Networks)
Last Update:
Word Count:
Read Time:
Page View: loading...
写在前面
作为博客开篇,Graph系列的第一章,一切都只是我浅薄的观察和对于阅读的部分论文得出的见解,不能说是insight,只能够尽可能从我自己的武断认为其可能存在的道理来进行剖析,以及,我特别喜欢的,从发展中向后推进、以预判其潜在的改进空间。
由于是第一章节,所以会牵扯到很多最最基础的定义,烦请耐心阅读。
另外,就我对于工业界的实习来看,至少在2025年,当下的图结构数据的开发依然存在极其大的空间。在实际应用中发挥图结构的优势,最最重要的是建模,因为图不再是简单的离散点阵,更有图的结构——这也牵扯到什么是图什么是异构图。即,并非再是像朴素数据挖掘那样探讨如何处理图结构的数据来适应一个自回归任务,而是在于应当如何去构建图结构的数据,去定义什么是边,什么是节点,甚至隐式地定义图。一个非常简单的例子,如何教会机器人通过有限旋转关节的机械臂,来叠衣服,如果说这个方法可以通过将空间和衣服本身建模用点来进行建模的话。也许很多人会有和我一样的疑惑:是否图结构的数据在很多的算法中其实都有所崭露,而只是被其他角度的解读所掩盖了。
GNN作为一个受到MLP和CV中的卷积神经网络的启发,而从深度学习的角度来建模图结构数据的将其作为一个从图数据到目标域的映射,这般的类推是十分朴实的,但是不可避免的需要“具体问题具体分析”——不是一个通用的网络就能够在所有的图相关任务中都达到最好的效果,就像是大语言模型需要在目标域进行微调一样。
好,那么下面开始。
参考
原文:(GCN-3 KipfNet)Semi-Supervised Classification with Graph Convolutional Networks ICLR2017 | Paper | Cite
代码: torch_geometric.nn.models.GCN
I. 图结构数据定义
常见的定义有二
定义一:基于几何结构
数学表示
一个图 () 由以下组成:
- 节点集合 (): 表示图中的所有节点,通常用 () 表示节点的数量。
- 边集合 (): 表示节点之间的连接关系,每条边由一对节点 () 表示。
- 节点特征矩阵 ():,其中表示每个节点的特征维度。
- 几何结构(可选): 边的几何信息,如在二维或三维空间中的边的长度、方向等。
形式化表示:
示例:
- ;
- ;
- =;
- 边的几何长度:。
定义二:基于邻接矩阵
数学表示:
一个图可以用以下方式定义:
- 邻接矩阵 : 表示图的拓扑结构,是一个的稀疏矩阵(一般来说),其中:
- 表示节点和之间存在边;
- 表示节点和之间不存在边。
- 节点特征矩阵 : 表示每个节点的特征,是一个,其中表示每个节点的特征维度。
- 边特征矩阵 (可选): 表示边的特征,是一个,其中表示每条边的特征维度。
形式化表示:
示例
;
;
(如边的权重或距离信息 )。
定义一关注几何结构,常用于需要明确空间信息的问题,如三维物体重建、分子建模和机器人路径规划,解决几何形状分析、分子性能预测和空间导航等问题;定义二更加关注节点信息和节点间的信息关系,广泛应用于社交网络、推荐系统和知识图谱,主要解决关系建模、个性化推荐以及复杂网络中信息传播与预测的问题。
当然了在现在的很多工业应用当中抛弃显式的图结构,用简单的神经网络和序列建模Transformer类似的交叉注意力结构也依然能够得到一个非常好的效果,因为大部分工业应用中更加重视速度——尽管这个速度可以是通过学术界新创新方法之后不断地优化得到的。
II. GCN原理
图卷积网络可以分解为层的堆叠,其思路非常简单可以概括为:
数学形式如下:
- :带自环的邻接矩阵
- :的度矩阵,意味着对于其中所有的非零元素都取正平方根的倒数;
- 入度矩阵(有向图,指向该节点的边):,
- 出度矩阵(有向图,从该节点指出的边):,
- :第层的节点特征, ;
- :可训练权重矩阵;
- :激活函数(如ReLU)。
III. 不同角度的Rationale
可以说,这是通过推广卷积和其上的拉普拉斯算子到图上,来将其变换到频域来进行计算,【Xavier Bresson教授图神经网络系列讲座_bilibili,图神经网络理论基础-人大-魏哲巍_bilibili】这是合理的。也可以从深度学习的角度出发(当然这也是深度卷积网络),所谓浅层表示local,深层表示global信息,即低频率特征值和高频特征值。
关注II部分中的公式.(2.1)中的部分:
本质上就是一个对于邻居节点和自身的加权平均,堆叠GNN的层可以看作是一个信息聚合的过程,如下图所示(有颜色的即为经过这次聚合后能够得到的信息):
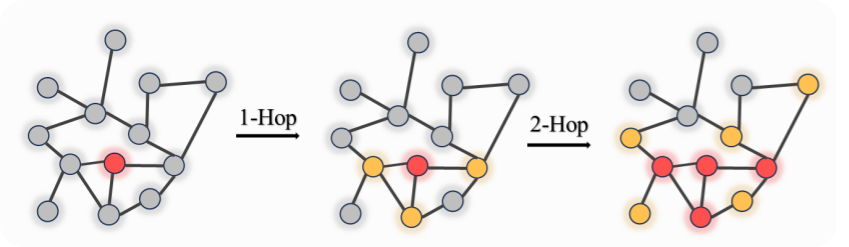
这样的邻居聚合后共享参数其实蕴含了三个假设,
- 第一,邻居节点和该节点的分类结果是相关的,这一假设与马尔科夫性质(Markov Property)相关,即一个节点的状态只依赖于其邻居节点的状态,也就会引出一些有关于马尔科夫毯(Markov blanket)的讨论,同时也引导人们看向诱导子图(Induced Graph)。
- 第二,如果构建的是一个深度GNN,节点间的最短距离和相关性呈反比,即图信号处理中的平滑性假设(Smoothness Assumption):图信号在局部区域内变化较小,也就是假设图信号的主要信息集中在低频部分,即图信号在局部区域内变化较小;
- 第三,假设节点的特征和边的权重是独立的,即边的权重只反映节点之间的连接强度,而不直接依赖于节点特征,这也是为什么GCN原文用的是在社交图上的半监督的节点分类问题。
可以说这三个假设是使得GCN这样的模式能够发挥作用的事后解释;也可以说是在发现其存在的问题之后的回顾,对于问题暂且先按下不表,先来看为什么他会有用,以及,是如何设计得更加符合神经网络工学的直觉的。
这和图像卷积中的每次一个滑窗聚合其中的的窗口内的像素点;抑或是信号与系统中的空域信号作倒序卷积,都有异曲同工之妙。
重新定义图卷积(Graph Convolution)
回顾一下卷积定义,其中是连续时域变量,是窗口大小。
离散版本, 是窗口大小, 是点列变量(离散时间),:
卷积只是一种频域的分析方法,用滤波器来筛选原来信号函数的性质,那么,如何定义Graph上的卷积呢,我们只关注其中的任意一点n,观察对于它卷积的时候发生了什么:
假设我们有以下输入信号 和卷积核 :
- 输入信号 ,索引范围为 ;
- 卷积核 ,索引范围为 。
首先,将卷积核 翻转:,我们取其中非零的点来计算: - 当 :
- 卷积核覆盖的范围:。
- 有效范围:。
- 计算得到即,其中为哈德玛积,即逐个位置元素相乘。
其上得到的是最后整个卷积后得到的函数的其中一个单位点,那么如果我们如果需要在图上定义什么是卷积,就需要定义什么是窗口?以及如何计算整个窗口内的各个元素的相加?
对于单个节点,他的相邻的数据,显然,就是其相邻的节点,他们靠边来连接,因此很自然地,图卷积的定义就是
就这么简单。
举栗.e.g.
将矩阵可视化就是(假设是一个无向的图):
| 节点1 | 节点2 | 节点3 | 节点4 | … | 节点属性1 | 属性2 | … | |||
|---|---|---|---|---|---|---|---|---|---|---|
| 节点1 | 1 | 0 | 1 | 0 | 节点1 | blabla | lbaba | labda | ||
| 节点2 | 0 | 1 | 0 | 0 | 节点2 | blala | lbaba | … | ||
| 节点3 | 1 | 0 | 1 | 1 | 节点3 | blaa | lba | |||
| 节点4 | 0 | 0 | 1 | 1 | 节点4 | babla | lbdab | |||
| … | … | … | … |
将这个和矩阵点积后可以得到更新后的
其中(比如第一个节点的更新后的第一个属性,关注红色的行和列哈德玛积后相加),
这里表示和原图中的节点的1-hop邻居节点。
那具体的步骤解释了,如何形式分析和定义呢?指路这家:图神经网络(GNN)入门之旅(三)-拉普拉斯矩阵与GCN - 知乎 (zhihu.com);(看里面怎么定义拉普拉斯的就够了嗷,不要贪杯= ^ =)。简述就是希望模仿二维离散的拉普拉斯算子(如下),来推广图上的卷积和频谱分析:
最最重要的是以下的这句话:
“”
假设具有 个节点的图 ,此时图中每个节点的自由度至多为 ,此时该图为完全图,即任意两个节点之间都有一条边连接,则对其中一个节点进行微扰,它可能变为图中任意一个节点。
此时以上定义的函数 不再是二维,而是 维向量: ,其中 为函数 在图中节点 处的函数值。类比于二维函数 在节点 处的值。
对 节点进行扰动,它可能变为任意一个与它相邻的节点 表示节点 的一阶邻域节点。
我们上面已经知道拉普拉斯算子可以计算一个点到它所有自由度上微小扰动的增益,则通过图来表示就是任意一个节点 变化到节点 所带来的增益……
“”
也就是:图卷积是定义在图的边结构上的卷积,而 ,所有的节点都是来自于一个分布的采样;这其实也和其他的离散的信号定义保持了一致,但是其奥妙在于他是基于边的结构的卷积。
但是显然地,我们会发现一个问题,在CV中,假设从函数的角度出发来看张量的变化, ,其输入和输出的张量形状是不一致的,即 的时候 ,也就是如果不padding的话,CNN的张量随着网络深度的增加是越来越小的。但是GNN并非如此, 的时候, ,始终都是节点的个数,那自然会出现问题:也就是(当然并没有那么显然哦,只是我说的)GCN会遇到的,过渡平滑。
IV. 图信号过渡平滑
拉普拉斯平滑原理
在图信号处理中,过渡平滑可通过图拉普拉斯矩阵量化,GCN传播一次的数学表达式为:
- ,就是上述的Section.III的最后的引言部分的定义,对于每个节点的变换后的值;
- ,图信号向量;
- , (姑且这样定义,也可以是归一化后的)组合拉普拉斯矩阵。
因为拉普拉斯矩阵就是来刻画局部的平滑度,详见图像中运用了拉普拉斯核后的图像。
平滑传播过程
在图卷积网络中,多层传播导致的平滑效应可表示为:
对传播矩阵(因为假设是拉普拉斯矩阵)进行特征分解:
经过次传播后:
平滑动态特性
那么自然地,从单个特征值的角度来看:
- 高频分量衰减:;
- 低频分量保留:。
过度平滑的数学描述
当传播次数时,信号收敛至:
其中是的主特征向量,导致节点特征趋同:
或者这样表示:
- 设 表示节点 在第 层的特征;
- 如果对于任意两个节点 和 ,有:或者通过方差来刻画:
V. 小结
Kipf的GCN其实不是GCN的最初的频谱分析的流派的继承,而是做出了简单而且大胆的创新,虽然一开始是无向图,但是可以推广到有向图;
其次是它的计算本质上是可以很快的,因为一切都取决于GPU上对于矩阵的点积操作的优化,但是,在大规模图上他的内存复杂消耗会到 因为相当于直接存入邻接矩阵,而且稀疏图一般都是用链表或者是字典结构数据来存储的,因此不同存储的转化也存在加速的可能性;
模型不具有随机性,没有独属于Graph的结构的数据增强和适合图的随机性对于方差的扩充。也就是,模型的泛化性不足 ———— 在OOD和存在分布偏移的数据上的泛化能力不足、对于动态图的适应能力较差。可以说这是由于他是transductive(直推)的,但是我不喜欢这种说辞,因为后续所谓提出inductive(归纳)方式解决了这个问题的GraphSAGE,实际上在动态图或者是分布差异的数据上的表现也不佳。
虽然这也是其他所有的想要作更好的representation learning的模型的通病,这也有待后续的更多博客来探讨。博客文笔见疏,诸君评论多加指正。